
type
status
date
slug
summary
tags
category
icon
password
日期
时长
重点
入门安装设置基础调用提示模板LLMChain代理(Agents)快速入门代理类型zero-shot-react-descriptionreact-docstoreself-ask-with-searchconversational-react-description自定义代理带工具检索的自定义代理环境设置设置工具工具检索器聊天自定义代理MRKL自定义代理代理执行器结合代理与向量库异步代理输出中间步骤限制最大迭代次数限制最大使用时长增加对话内存(SharedMemory)工具包(Toolkits)CSV 代理Python代理工具(Tools)现有工具列表自定义工具链(Chains)入门链内存链的指南链的异步LangChainHub加载多提示词选择链多问答库选择链索引实例分析文档索引入门索引的创建文档加载器(Document Loaders)BiliBiliLoader(没成功)文本分割器(Text Splitters)入门向量存储(Vectorstores)入门功能检索器(Retrievers)Databerry记忆存储(Memory)入门聊天记录缓冲记忆链中使用储存消息多输入内存链(文档,真人query)带内存的Agent数据库类内存Agent模型(Models)聊天模型入门指南PromptTemplates流处理少量示例(few shot)文本嵌入(Text Embedding)OpenAI 嵌入类Hugging Face 嵌入类提示工程(prompts)输出解析器入门用例(User Case)智能体仿真(Agent Simulations)单代理 Gymnasium定义代理初始化模拟环境和代理主循环双代理模拟 CAMELCAMEL基础介绍导入Langchain相关模块定义CAMEL代理辅助类设置角色和角色扮演任务创建指定任务的代理人进行头脑风暴并获取指定任务创建AI助手和AI用户的启发式提示,用于角色扮演创建一个帮助程序,从角色名称和任务中获取AI助手和AI用户的系统消息从获得的系统消息创建AI助手代理和AI用户代理开始角色扮演环节来解决问题多代理模拟自定义发言顺序代理竞价发言顺序特权代理指定发言顺序带记忆的多代理自主代理 Autonomous_agents
入门

安装设置
先下载 langchain包然后设置系统OpenAI API参数(以下默认使用Open AI)
基础调用
提示模板
LLMChain
我们现在可以创建一个非常简单的链: 它接受用户输入,用它格式化提示符,然后将它发送到 LLM:
代理(Agents)
有些应用程序不仅需要预先确定的LLM/其他工具调用链,而且可能需要根据用户输入的不同而产生不同的链条。
在这些类型的链条中,有一个“代理人”可以访问一套工具。
根据用户输入,代理人可以决定是否调用其中任何一个工具。
快速入门
由于以下工具主要使用的是google search的SerpAPi,建议先去注册该服务
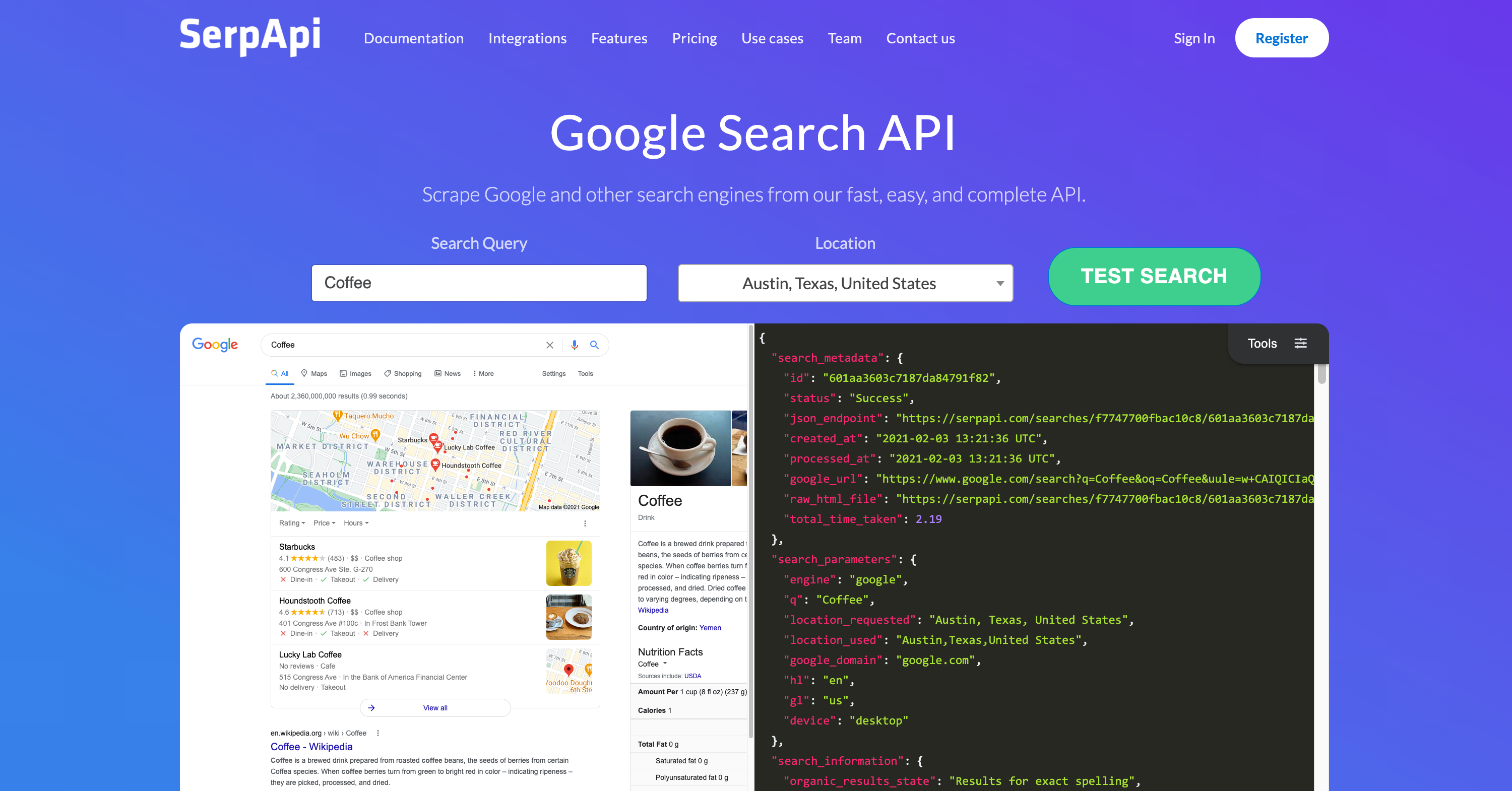
为了加载代理,您应该了解以下概念:
- 工具:执行特定职责的函数。这可以是诸如:Google搜索、数据库查找、Python REPL、其他链等。工具的接口目前是期望有一个字符串作为输入,一个字符串作为输出的函数。
- LLM:为代理提供动力的语言模型。
- 代理:要使用的代理。这应该是一个引用支持代理类的字符串。
首先进行预定义
其次,加载一个LLM语言模型
接下来,让我们加载一些要使用的工具。请注意,
llm-math工具使用LLM,因此我们需要传递它。最后,让我们使用工具、语言模型和我们想要使用的代理人类型初始化一个代理人。
代理类型
4类基础代理(都是用ReAct框架实现)+自定义
zero-shot-react-description
此代理使用ReAct框架,仅基于工具的描述来确定要使用的工具。
可以提供任意数量的工具。
此代理需要为每个工具提供描述。
react-docstore
这个代理使用ReAct框架与文档存储进行交互。
必须提供两个工具:一个
Search工具和一个Lookup工具(它们必须被命名为这样)。Search工具应该搜索文档,而Lookup工具应该查找最近找到的文档中的一个术语。这个代理使用ReAct框架与文档存储进行交互。
这个代理相当于最初的ReAct论文(opens in a new tab),特别是维基百科的例子。
self-ask-with-search
这个代理使用一个被命名为
Intermediate Answer的工具。这个工具应该能够查找问题的事实性答案。
这个代理相当于最初的self ask with search paper(opens in a new tab),其中提供了Google搜索API作为工具。
conversational-react-description
这个代理程序旨在用于对话环境中。提示设计旨在使代理程序有助于对话。 它使用ReAct框架来决定使用哪个工具,并使用内存来记忆先前的对话交互。
自定义代理
一个代理 (Agent) 由二个部分组成:
- 工具 tool:代理可以使用的工具。
- 代理执行器 :这决定了采取哪些行动。
以下是自定义代理的流程,需要基于BaseSingleActionAgent类
带工具检索的自定义代理
当你有很多工具可供选择时,这非常有用。你不能在提示中放置所有工具的描述(由于上下文长度问题),因此你动态选择你想要在运行时考虑使用的N个工具。
我们将有一个合适的工具(搜索),然后99个假工具,这只是废话。
然后,我们将在提示模板中添加一个步骤,该步骤接受用户输入并检索与查询相关的工具。
环境设置
设置工具
创建一个合适的工具(搜索)和99个不相关的工具。
工具检索器
我们将使用向量存储来为每个工具描述创建嵌入。
然后,对于传入的查询,我们可以为该查询创建嵌入,并进行相关工具的相似性搜索。
接下来可以测试这个检索器了
聊天自定义代理
LLM聊天代理由三个部分组成:
- PromptTemplate:这是用于指示语言模型该做什么的提示模板
- ChatModel:这是驱动代理的语言模型
stop序列:指示LLM在找到此字符串时停止生成
- OutputParser:确定如何将LLM输出解析为AgentAction或AgentFinish对象。
LLMAgent用于代理执行器。这个代理执行器在很大程度上可以看作是一个循环:
- 将用户输入和任何先前的步骤传递给代理(在这种情况下是LLMAgent)
- 如果代理返回
AgentFinish,则将其直接返回给用户。
MRKL自定义代理
MRKL Agent由三个部分组成:
- 工具:代理可用的工具。
- LLMChain:生成以一定方式解析的文本,以确定要采取哪个动作。
- 代理类本身:解析LLMChain的输出,以确定要采取哪个动作。
代理执行器
代理执行器将代理和工具结合使用,并使用代理来决定调用哪些工具以及按什么顺序调用。
在文档的这个部分,我们介绍了与代理执行器相关的其他功能:
结合代理与向量库
本文介绍如何结合代理和向量库。这样做的用例是,您已将数据摄入到向量库中,并希望以代理方式与其进行交互。
建议的方法是创建一个
RetrievalQA,然后将其作为整体代理的工具。让我们来看看如何在下面执行此操作。您可以使用多个不同的向量数据库执行此操作,并使用代理作为它们之间路由的方法。
有两种不同的方法可以做到这一点-您可以让代理像正常工具一样使用向量库,也可以设置
return_direct=True,以实际将代理仅用作路由器。创建向量库
创建代理
运行即可显示出在指定文件或指定网页中(存入向量数据库)中存在的内容。
异步代理
输出中间步骤
限制最大迭代次数
Agent参数设置
max_iterations=2 即可限制最大使用时长
Agent参数设置
max_execution_time=1即可增加对话内存(SharedMemory)
我们将创建一个自定义Agent,同时该Agent可以访问对话内存、搜索工具和摘要工具。而且,摘要工具还需要访问对话内存。
我们现在可以使用Memory对象构建LLMChain,然后创建Agent。
工具包(Toolkits)
众多的格式交互示例解决对应的问题

CSV 代理
本教程展示了如何使用代理与CSV交互,主要针对问题回答进行了优化。
注意:此代理在幕后调用Pandas DataFrame代理,后者调用Python代理,执行LLM生成的Python代码 - 如果LLM生成的Python代码有害,则可能会存在风险,请谨慎使用。
Python代理
工具(Tools)
工具是代理可以用来与世界互动的功能。这些工具可以是通用工具(例如搜索),其他链,甚至是其他代理。
目前,可以使用以下代码片段加载工具:
一些工具(例如链、代理)可能需要基础LLM来初始化它们。在这种情况下,也可以传入LLM:
面是所有支持的工具及相关信息的列表:
- Tool Name 工具名称:LLM用来引用该工具的名称。
- Notes 工具描述:传递给LLM的工具描述。
- Requires LLM 注意事项:不传递给LLM的工具相关注意事项。
- (Optional) Extra Parameters(可选)附加参数:初始化此工具需要哪些额外参数。
现有工具列表
自定义工具
以下是众多示例


Gradio 工具
人类AGI工具
人类具有AGI,因此当AI代理处于困惑状态时,它们可以作为工具来帮助。
在上面的代码中,您可以看到工具直接从命令行接收输入。您可以根据需要自定义
prompt_func 和 input_func(如下所示)。Wikipedia工具
链(Chains)
本教程以Agent实现为主,以下只做简单了解
入门
链允许我们将多个组件组合在一起,创建一个单一的、一致的应用程序。例如,我们可以创建一个链,该链接接受用户输入,使用 PromptTemplate 对其进行格式化,然后将格式化后的响应传递给 LLM。我们可以通过将多个链组合在一起,或者通过将链与其他组件组合在一起,来构建更复杂的链。
链内存
Chain 支持将 BaseMemory 对象作为其内存参数,允许 Chain 对象跨多个调用持久存储数据。换句话说,它使 Chain 成为一个有状态对象。
实际上,BaseMemory 定义了一个长链存储内存的接口。它允许通过 load _ memory _ variable 方法读取存储的数据,并通过 save _ context 方法存储新数据。
链的指南
仅举四个常见的,详见:https://www.langchain.asia/modules/chains
链的异步
LangChain通过利用asyncio库为链提供异步支持。
目前LLMChain(通过arun、apredict、acall)、LLMMathChain(通过arun和acall)、ChatVectorDBChain以及QA chains支持异步方法。其他链的异步支持正在路线图中。
LangChainHub加载
多提示词选择链
本教程演示了如何使用RouterChain范例创建一个链,它动态地选择用于给定输入的提示。具体来说,我们展示了如何使用MultiPromptChain创建一个问答链,该链选择与给定问题最相关的提示,然后使用该提示回答问题。
多问答库选择链
本教程演示如何使用
RouterChain 范例创建一个动态选择使用哪个检索系统的链。具体而言,我们展示了如何使用 MultiRetrievalQAChain 创建一个问答链,该链选择对于给定问题最相关的检索QA链,然后使用它回答问题。索引实例
分析文档
该链接收单个文档,将其拆分,然后通过合并文档链运行它。这可以用作更多的端到端链。
总结
问答
索引
入门
默认情况下,LangChain 使用 Chroma 作为向量存储来索引和搜索嵌入。要学习本教程,我们首先需要安装 chromadb。
索引的创建
- 加载文件
- 将文档分割成块
- 为每个文档创建嵌入
- 在向量数据库中存储文档和嵌入
接下来,我们将把文档分割成块。
然后,我们将选择要使用的嵌入。
现在我们创建用作索引的向量存储。
这就是创建索引的过程,然后,我们在一个检索接口中公开这个索引。
然后,像以前一样,我们创建一个链,并使用它来回答问题!
文档加载器(Document Loaders)
Langchian中提供了非常多

BiliBiliLoader(没成功)
这个加载器使用 bilibili-api(opens in a new tab) 来从
B站 获取文本转录。使用这个 BiliBiliLoader,用户可以轻松地获取平台上他们所需的视频内容的文字转录。我们试着选取了新国辩一场经典比赛的内容。


文本分割器(Text Splitters)
当您想处理长篇文本时,需要将文本拆分为块。 尽管听起来很简单,但这里存在着很多潜在的复杂性。理想情况下,您想将语义相关的文本片段保持在一起。什么是“语义相关”可能取决于文本类型。 本教程展示了几种方法来实现这一点。
在高层次上,文本分割器的工作如下:
- 将文本拆分为小的、语义上有意义的块(通常是句子)。
- 开始将这些小块组合成一个较大的块,直到达到一定的大小(由某些函数测量)。
- 一旦达到该大小,将该块作为自己的文本块,然后开始创建一个新的文本块,其中包含一些重叠(以保持文本块之间的上下文)。
这意味着您可以沿两个不同的轴自定义文本分割器:
- 文本如何拆分
- 如何测量块大小
入门
默认推荐的文本分割器是 RecursiveCharacterTextSplitter。该文本分割器需要一个字符列表。它尝试根据第一个字符分割创建块,但如果任何块太大,则移动到下一个字符,依此类推。默认情况下,它尝试分割的字符是
[" ", "\n", " ", ""]除了控制可以分割的字符之外,您还可以控制其他一些内容:
length_function: 如何计算块的长度。默认情况下只计算字符数,但通常在此处传递令牌计数器。
chunk_size: 块的最大大小(由长度函数测量)。
chunk_overlap: 不同文本块之间的最大重叠部分。保持文本块之间的一定连续性可能非常有用(例如,使用滑动窗口),因此一些重叠是很好的。
根据不同的领域需求,还有很多专门的分割器

向量存储(Vectorstores)
入门功能
添加文本
您可以使用
add_texts方法轻松地将文本添加到向量存储中。它将返回文档ID的列表(以防您需要在下游使用它们)。检索器(Retrievers)
检索器接口是一种通用接口,使文档和语言模型易于组合。该接口公开一个get_relevant_documents方法,该方法接受查询(字符串)并返回文档列表。
Databerry
Databerry是一个提供数据储存的网站
Langchain中还提供非常多

记忆存储(Memory)
入门
本教程详细介绍了 LangChain 对记忆的看法。
内存涉及在用户与语言模型的交互过程中始终保持状态的概念。用户与语言模型的交互被捕获在聊天消息的概念中,所以这归结为从一系列聊天消息中摄取、捕获、转换和提取知识。有许多不同的方法可以实现这一点,每种方法都作为自己的内存类型存在。
一般来说,对于每种类型的记忆,有两种方法来理解使用记忆。一是从消息序列中提取信息的独立函数,还有一种方法可以在链中使用这种类型的内存。
内存可以返回多条信息(例如,最近的 N 条消息和所有以前消息的摘要)。返回的信息可以是字符串,也可以是消息列表。
在本教程中,我们将介绍最简单的内存形式: “缓冲”内存,它仅仅涉及保持所有以前的消息的缓冲区。我们将在这里展示如何使用模块化实用函数,然后展示如何在链中使用它(既返回字符串,也返回消息列表)。
聊天记录
支撑大多数(如果不是全部)内存模块的核心实用工具类之一是 ChatMessageHistory 类。这是一个超轻量级的包装器,它提供了一些方便的方法来保存人类消息、人工智能消息,然后获取它们。
如果要管理链外部的内存,可能需要直接使用此类。
缓冲记忆
现在我们展示如何在链中使用这个简单的概念。我们首先展示 ConversationBufferMemory,它只是 ChatMessageHistory 的一个包装器,用于提取变量中的消息。
我们可以首先提取它作为一个字符串。
链中使用
最后,让我们看看如何在链中使用它(设置 verose = True,这样我们就可以看到提示符)。
储存消息
您可能经常需要保存消息,然后加载它们再次使用。通过首先将消息转换为普通的 python 字典,保存它们(作为 json 或其他形式) ,然后加载它们,利用
messages_from_dict 和 messages_to_dict很容易地做到这一点。这里有一个这样做的例子。多输入内存链(文档,真人query)
大多数内存对象都假设只有一个输入。在本文中,我们将介绍如何给具有多个输入的链添加内存。作为这样一条链的示例,我们将向问答链添加内存。该链将相关文档和用户问题作为输入。
带内存的Agent
为了为Agent添加内存,我们需要执行以下步骤:
- 我们将创建一个具有内存的LLMChain。
- 我们将使用该LLMChain创建自定义Agent。
为了完成此练习,我们将创建一个简单的自定义Agent,该Agent可以访问搜索工具,并使用
ConversationBufferMemory类。请注意,在PromptTemplate中使用
chat_history变量,该变量与ConversationBufferMemory中的动态键名匹配。现在,我们可以使用Memory对象构建LLMChain,然后创建代理。(锐评一下,LangChain的agent不能直接添加 memory,还得搞成 agent_chain)
数据库类内存Agent
模型(Models)
本文档的这一部分涉及到LangChain中使用的不同类型的模型。 在本页上,我们将对模型类型进行概述, 但我们为每种模型类型都有单独的页面。 这些页面包含更详细的“如何”指南, 以及不同模型提供商的列表。
LLMs
大型语言模型(LLMs)是我们首先介绍的模型类型。 这些模型将文本字符串作为输入,并返回文本字符串作为输出。
聊天模型
聊天模型是我们介绍的第二种模型类型。 这些模型通常由语言模型支持,但它们的API更加结构化。 具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
文本嵌入模型
我们介绍的第三种模型类型是文本嵌入模型。 这些模型将文本作为输入,并返回一个浮点数列表。
聊天模型
入门指南
本教程涵盖了如何开始使用聊天模型。该接口基于消息而不是原始文本。
通过向聊天模型传递一个或多个消息,您可以获得聊天完成。响应将是一条消息。LangChain目前支持的消息类型有
AIMessage、HumanMessage、SystemMessage和ChatMessage - ChatMessage接受任意角色参数。大多数情况下,您只需处理HumanMessage、AIMessage和SystemMessageOpenAI的聊天模型支持多个消息作为输入。有关更多信息,请参见此处(opens in a new tab)。下面是向聊天模型发送系统和用户消息的示例:
PromptTemplates
您可以通过使用
MessagePromptTemplate来利用模板。您可以从一个或多个MessagePromptTemplates构建一个ChatPromptTemplate。您可以使用ChatPromptTemplate的format_prompt - 这将返回一个PromptValue,您可以将其转换为字符串或消息对象,具体取决于您是否想要将格式化值用作llm或chat模型的输入。为了方便起见,模板上公开了一个
from_template方法。如果您使用此模板,它将如下所示:当然更方便的方法是直接在外部构建PromptTemplate然后传入
流处理
通过回调处理,
ChatOpenAI支持流处理。(推荐流处理,这样生成长文本时可以不断浏览而不需要长时间等待。少量示例(few shot)
进行few shot提示的第一种方法是使用交替的人类/ AI消息。请参见下面的示例。
文本嵌入(Text Embedding)
Embedding类是一个用于与嵌入进行交互的类。有许多嵌入提供商(OpenAI、Cohere、Hugging Face等)- 这个类旨在为所有这些提供商提供一个标准接口。
嵌入会创建文本的向量表示。这很有用,因为这意味着我们可以在向量空间中考虑文本,并执行诸如语义搜索之类的操作,其中我们在向量空间中寻找最相似的文本片段。
LangChain中的基本Embedding类公开了两种方法:embed_documents和embed_query。最大的区别在于这两种方法具有不同的接口:一个适用于多个文档,而另一个适用于单个文档。除此之外,将这两个方法作为两个单独的方法的另一个原因是,某些嵌入提供商针对要搜索的文档与查询本身具有不同的嵌入方法。
OpenAI 嵌入类
Hugging Face 嵌入类
让我们加载Hugging Face嵌入类。
提示工程(prompts)
具体的提示模板 前面差不多都有过示例,这里重点解析一下输出解析器(Output Parsers)
输出解析器
入门
语言模型输出文本。但是很多时候,你可能想要获得比文本更结构化的信息。这就是输出解析器的作用。
输出解析器是帮助结构化语言模型响应的类。有两种主要的方法,一个输出解析器必须实现:
get_format_instructions() -> str:一个方法,返回一个包含有关如何格式化语言模型输出的字符串。
parse(str) -> Any:一个方法,接受一个字符串(假定为语言模型的响应)并将其解析为某个结构。
然后是一个可选的:
-
parse_with_prompt(str, PromptValue) -> Any:该方法接受一个字符串(假定为语言模型的响应)和一个提示(假定为生成此类响应的提示),然后将其解析成某种结构。提示在很大程度上是提供的,以防OutputParser希望以某种方式重试或修复输出,并需要提示信息来执行此操作。
下面我们介绍主要类型的输出解析器——
PydanticOutputParser。其他选项请参见examples文件夹。用例(User Case)
用例精选一些实用的:
- 智能体仿真
智能体仿真(Agent Simulations)
代理模拟涉及将一个或多个代理与彼此交互。代理模拟通常涉及两个主要组件:
- 长期记忆
- 模拟环境
代理模拟的具体实现(或代理模拟的部分)包括:
单代理模拟:
• 模拟环境:Gymnasium :演示如何使用Gymnasium(opens in a new tab)(前OpenAI Gym(opens in a new tab))创建一个简单的代理-环境交互循环。
两个代理模拟:
- CAMEL: 实现了CAMEL(Communicative Agents for “Mind” Exploration of Large Scale Language Model Society)论文,两个代理人进行交流。
- Two Player D&D: 展示了如何使用通用的两个代理人模拟器来实现流行的龙与地下城角色扮演游戏的变体。
多代理模拟:
- Multi-Player D&D: 介绍了如何使用通用的对话模拟器为多个对话代理人编写一种自定义的演讲顺序,演示了流行的龙与地下城角色扮演游戏的变体。
- Decentralized Speaker Selection: 展示了如何在没有固定讲话顺序的多代理人对话中实现多代理人对话的例子。代理人使用竞价来决定谁发言。该实例以虚构的总统辩论为例展示了如何实现。
- Authoritarian Speaker Selection: 展示了如何实现多代理人对话,其中特权代理指定谁讲什么。 实例还展示了如何使特权代理确定对话何时终止。该实例以虚构的新闻节目为例展示了如何实现。
- Generative Agents: 该教程实现了一种基于论文“Generative Agents: Interactive Simulacra of Human Behavior”(Park等人)的生成代理人。
单代理 Gymnasium
对于LLM代理的许多应用,环境是真实的(互联网数据库REPL等)。
但是,我们也可以定义代理以与基于文本的游戏等模拟环境进行交互。
定义代理
以下代码定义了一个名为
GymnasiumAgent的类。该类是一个用于和环境(可能是一个游戏或者模拟环境)交互的智能代理。它接收环境的观察值(observation),并根据这些观察值选择一个动作(action),这个动作会被应用到环境上,然后环境会给出新的观察值和奖励(reward)。以下是这个类的主要部分的解释:
- 类方法
get_docs(cls, env):这个方法接受一个环境对象,并返回环境的文档字符串。
__init__(self, model, env):这是类的初始化方法,它接受一个模型对象和一个环境对象。模型对象用于根据观察值选择动作,环境对象用于提供观察值和奖励,以及接收动作。
random_action(self):这个方法返回一个随机动作。动作是从环境的动作空间中随机采样得到的。
reset(self):这个方法用于重置代理的状态,包括消息历史和返回值。
observe(self, obs, rew=0, term=False, trunc=False, info=None):这个方法接受一个观察值、一个奖励值、一个终止标志、一个截断标志和一些额外的信息,然后更新代理的状态,并返回一个观察信息的消息。
_act(self):这个方法调用模型的预测方法,得到一个动作的消息,然后解析这个消息,得到动作的值。
act(self):这个方法尝试调用_act方法得到一个动作的值。如果_act方法抛出一个ValueError异常,那么它会重试一次。如果重试还是失败,那么它会返回一个随机动作。
这个类使用了
tenacity库来实现重试逻辑,这是一个用于处理失败和重试的Python库。它还使用了RegexParser来解析动作的消息,这是一个使用正则表达式来解析字符串的工具。总的来说,这个类是一个用于和环境交互的智能代理的实现。它可以根据环境的观察值选择动作,并处理环境的反馈,包括奖励和新的观察值。
初始化模拟环境和代理
主循环
双代理模拟 CAMEL
CAMEL基础介绍
这是一份论文的langchain实现: 《CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society”》
概览:
会话和聊天语言模型的迅速发展已经在复杂任务解决方面取得了显著进展。
然而,它们的成功严重依赖于人类的输入来引导对话,这可能会很具挑战性和耗时。
本文探讨了在沟通代理之间建立可扩展的技术来促进自治合作并为其“认知”过程提供洞察的潜力。
为了解决实现自治合作的挑战,我们提出了一种新的沟通代理框架,称为角色扮演。
我们的方法涉及使用启动提示来引导聊天代理完成任务,同时保持与人类意图的一致性。
我们展示了角色扮演如何用于生成会话数据,以研究聊天代理的行为和能力,为研究会话语言模型提供了有价值的资源。
我们的贡献包括引入了一种新颖的沟通代理框架,提供了一种可扩展的方法来研究多代理系统的合作行为和能力,以及开源了我们的库以支持对沟通代理和其他内容的研究。
Arxiv paper: https://arxiv.org/abs/2303.17760
导入Langchain相关模块
定义CAMEL代理辅助类
以下这段代码定义了一个名为
CAMELAgent 的类。这个类看起来像是一个聊天机器人代理,它可以接收和发送消息。以下是这个类的主要部分的解释:
__init__(self, system_message: SystemMessage, model: ChatOpenAI) -> None:这是类的初始化方法,它接受一个系统消息对象和一个聊天模型对象。系统消息可能是用于初始化聊天会话的消息,聊天模型用于生成回复消息。
reset(self) -> None:这个方法用于重置代理的状态,包括存储的消息。它返回重置后的消息列表。
init_messages(self) -> None:这个方法初始化存储的消息列表,它只包含一个系统消息。
update_messages(self, message: BaseMessage) -> List[BaseMessage]:这个方法接受一个消息对象,将它添加到存储的消息列表中,并返回更新后的消息列表。
step(self, input_message: HumanMessage) -> AIMessage:这个方法是代理的主要工作方法。它接受一个人类消息对象,使用聊天模型生成一个AI消息对象,并返回这个消息对象。在生成AI消息之前和之后,它都会更新存储的消息列表。
这个类的主要工作流程是:接收一个人类消息,使用聊天模型生成一个AI消息,然后返回这个AI消息。在这个过程中,它会持续更新存储的消息列表。这个列表可能会被用于聊天模型生成回复消息,也可能会被用于其他目的,比如日志记录或者调试。
设置角色和角色扮演任务
创建指定任务的代理人进行头脑风暴并获取指定任务
创建AI助手和AI用户的启发式提示,用于角色扮演
创建一个帮助程序,从角色名称和任务中获取AI助手和AI用户的系统消息
从获得的系统消息创建AI助手代理和AI用户代理
开始角色扮演环节来解决问题
多代理模拟
自定义发言顺序
• Multi-Player D&D: 介绍了如何使用通用的对话模拟器为多个对话代理人编写一种自定义的演讲顺序,演示了流行的龙与地下城角色扮演游戏的变体。
代理竞价发言顺序
• Decentralized Speaker Selection: 展示了如何在没有固定讲话顺序的多代理人对话中实现多代理人对话的例子。代理人使用竞价来决定谁发言。该实例以虚构的总统辩论为例展示了如何实现。
特权代理指定发言顺序
• Authoritarian Speaker Selection: 展示了如何实现多代理人对话,其中特权代理指定谁讲什么。 实例还展示了如何使特权代理确定对话何时终止。该实例以虚构的新闻节目为例展示了如何实现。
带记忆的多代理
• Generative Agents: 该教程实现了一种基于论文“Generative Agents: Interactive Simulacra of Human Behavior”(Park等人)的生成代理人。
- 记忆形成
生成式代理具有扩展的记忆,将多个存储为单个流:
- 1.观察 - 来自对话或与虚拟世界的交互有关自己或他人的事情
- 2.反思 - 重新涌现和总结核心记忆
- 记忆召回
记忆是通过重要性,最近性和显著性的加权和来检索的。
你可以在参考文档中查看以下导入的
GenerativeAgent和GenerativeAgentMemory的定义,重点关注add_memory和summarize_related_memories方法。自主代理 Autonomous_agents
自主代理是旨在更长期运行的代理。 您向它们提供一个或多个长期目标,它们会独立地朝着这些目标执行。 应用程序结合了工具使用和长期记忆。
目前,自主代理还处于相对实验性阶段,基于其他开源项目。
通过在LangChain原语中实现这些开源项目,我们可以获得LangChain的好处,包括易于切换和尝试多个LLM、使用不同的向量存储器作为内存、使用LangChain的工具集。
- 作者:KashiwaByte
- 链接:https://www.kashiwabyte.tech/article/langchain_learn
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。